
Macs don’t get much love in the forensics community, aside from @iamevltwin (Sarah Edwards), @patrickolsen (Patrick Olsen), @patrickwardle (Patrick Wardle), and a few other incredibly awesome pioneers in the field. We see blog posts all the time about Windows forensics and malware analysis techniques, along with some Linux forensic analysis, but rarely do we see any posts about Mac technical/forensic analysis or techniques. I find this odd, considering the surge in usage and deployment over the last several years, particularly within enterprises. Well, with my most recent two part Mac post as well as this one, I’m attempting to change this, my friends!
Macs need love and disk/memory analysis as well, amirite?
Let’s have a look at memory acquisition of OSX systems using a nifty tool called OSXpmem.
OSXpmem is a part of the pmem suite created by the developers of Rekall. Rekall itself is actually a very useful utility built for both memory acquisition and live memory analysis on Windows, Linux, and OSX systems. While I will be delving into Rekall in a future post, for this we will simply be focusing on OSXpmem, which is an awesome command-line utility for quickly and easily collecting RAM from a Mac system. One of its greatest features is its output to an AFF4 volume, which has a ton of useful features (likely to be discussed in a dedicated post in the future as well).
Acquiring Memory
So, what’s the easiest way to get up and running with the tool for memory acquisition?
- Download latest release (as of this post, the latest osxpmem release is “2.1.post4”).
- Unzip the package
$ unzip osxpmem.osxpmem-2.1.post4.zip
- Run it to collect memory from the local system
$ ./osxpmem.app/osxpmem -o <output_dir>
Super simple, right?
Wellll, maybe not that simple. When you run it, even as sudo/root, you may get the following error:
$ sudo osxpmem.app/osxpmem -o Memory_Captures/mem.aff4
Imaging memory
E1229 15:17:26.335978 3375588288 aff4_file.cc:289] Can not open file /dev/pmem :No such file or directory
/Users/jp/Projects/osxpmem.app/MacPmem.kext failed to load - (libkern/kext) authentication failure (file ownership/permissions); check the system/kernel logs for errors or try kextutil(8).
E1229 15:17:26.606639 3375588288 osxpmem.cc:283] Unable to load driver at /Users/jp/Projects/osxpmem.app/MacPmem.kext
E1229 15:17:26.606714 3375588288 pmem_imager.cc:328] Imaging failed with error: -8
How usefully nondescript. Let me save you some time, as searching the system/kernel logs as suggested yields nothing useful.
So, instead, let’s use the native utility kextutil’s “test” parameter (-t) to see if that gets us anywhere…
$ sudo kextutil -t osxpmem.app/MacPmem.kext/
Diagnostics for osxpmem.app/MacPmem.kext:
Authentication Failures:
File owner/permissions are incorrect (must be root:wheel, nonwritable by group/other):
osxpmem.app/MacPmem.kext
Contents
_CodeSignature
CodeResources
Info.plist
MacOS
MacPmem
Nice. It finally tells us what’s wrong. The file ownership/permissions must be changed to “root:wheel”. Easy enough…
$ sudo chown -R root:wheel osxpmem.app/
So, let’s try again…
$ sudo osxpmem.app/osxpmem -o Memory_Captures/mem.aff4
Imaging memory
Creating output AFF4 ZipFile.
Reading 0x8000 0MiB / 8095MiB 0MiB/s
Reading 0xe38000 14MiB / 8095MiB 56MiB/s
Reading 0x1c88000 28MiB / 8095MiB 56MiB/s
Reading 0x2ac0000 42MiB / 8095MiB 56MiB/s
Reading 0x3978000 57MiB / 8095MiB 58MiB/s
Reading 0x47c8000 71MiB / 8095MiB 56MiB/s
Reading 0x5678000 86MiB / 8095MiB 58MiB/s
Reading 0x6500000 101MiB / 8095MiB 57MiB/s
…
Reading 0x1f7478000 8052MiB / 8095MiB 39MiB/s
Reading 0x1f7d68000 8061MiB / 8095MiB 35MiB/s
Reading 0x1f8708000 8071MiB / 8095MiB 38MiB/s
Reading 0x1f9150000 8081MiB / 8095MiB 41MiB/s
Reading 0x1f9c00000 8092MiB / 8095MiB 41MiB/s
YES! It worked! As you can see, my system has 8GB of memory that was (by default) exported to an AFF4 volume/file called “mem.aff4”.
You also have the option to include additional local files within the resulting AFF4 volume/file via the “-i </path/to/file> -i </path/to/file> …” command line option(s), which can be useful in producing a singular output volume containing not only memory but other files (binaries/logs/etc.) you’d like to analyze as well. In the past, I used this option to collect the local /bin/bash file when Volatility used to require the bash shell’s memory address be provided in order to parse command history and produce associated timestamps when using the linux_bash plugin. Though the documentation still shows it as a requirement, it’s actually not needed anymore and parses it all just fine.
In addition, you may also export the memory image to a singular RAW or ELF file by using the “–format elf” or “–format raw” command line options if that suits your fancy. However, for this post, I am using the default AFF4 output so that we may explore its use and features a bit.
So, without further ado, let’s take a look at the resulting AFF4 volume/file.
$ sudo osxpmem.app/osxpmem -V Memory_Captures/mem.aff4
Password:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix aff4: <http://aff4.org/Schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix memory: <http://aff4.org/Schema#memory/> .
<aff4://7f482355-5683-46bb-87c0-21afd75dbbeb/dev/pmem>
aff4:category memory:physical ;
aff4:stored <aff4://7f482355-5683-46bb-87c0-21afd75dbbeb> ;
a aff4:map .
<aff4://7f482355-5683-46bb-87c0-21afd75dbbeb/dev/pmem/data>
aff4:chunk_size 32768 ;
aff4:chunks_per_segment 1024 ;
aff4:compression <https://www.ietf.org/rfc/rfc1950.txt> ;
aff4:size 8488656896 ;
aff4:stored <aff4://7f482355-5683-46bb-87c0-21afd75dbbeb> ;
a aff4:image .
Objects in use:
Objects in cache:
aff4://7f482355-5683-46bb-87c0-21afd75dbbeb - 0
aff4://7f482355-5683-46bb-87c0-21afd75dbbeb/information.turtle - 0
file:///Users/jp/Projects/Memory_Captures/mem.aff4 - 0
Here, you can see that we extracted a memory image to the AFF4 stream “7f482355-5683-46bb-87c0-21afd75dbbeb/dev/pmem“.
Now, what can we do with this? Well, one thing you could do (if not using Rekall to analyze this image) might be to extract the AFF4 memory image stream into a singular raw file for parsing/analysis by other tools such as Volatility, page_brute, yara, strings, etc. To do that, we perform the following:
$ sudo osxpmem.app/osxpmem -e /dev/pmem -o Memory_Captures/mem.raw Memory_Captures/mem.aff4
Extracting aff4://7f482355-5683-46bb-87c0-21afd75dbbeb/dev/pmem into file:///Users/jp/Projects/Memory_Captures/mem.raw
Reading 0x8000 0MiB / 9968MiB 0MiB/s
Reading 0x750000 7MiB / 9968MiB 28MiB/s
Reading 0xde0000 13MiB / 9968MiB 25MiB/s
Reading 0x1480000 20MiB / 9968MiB 25MiB/s
…
Reading 0x26d938000 9945MiB / 9968MiB 21MiB/s
Reading 0x26deb8000 9950MiB / 9968MiB 21MiB/s
Reading 0x26e418000 9956MiB / 9968MiB 20MiB/s
Reading 0x26eab0000 9962MiB / 9968MiB 25MiB/s
$ ls -l Memory_Captures/
total 25665056
-rwxr-xr-x 1 root staff 2688302741 Dec 29 15:30 mem.aff4
-rwxr-xr-x 1 root staff 10452205568 Dec 29 16:10 mem.raw
As you can see, the raw image is uncompressed and thus substantially larger than the AFF4 volume (one of the useful features of AFF4 is its compression options). Nonetheless, there you have it. A raw memory image to parse to your heart’s content with whatever tools you like.
However, before we move on, I personally like to unload the kernel extension for one last good measure so that it’s not just hanging out there for no purpose.
$ sudo osxpmem.app/osxpmem -u
Unloading driver /Users/jp/Projects/osxpmem.app/MacPmem.kext
Creating a Memory Profile
**Update 11/2019**
The dwarfdump conversion process using Volatility’s convert.py utility is broken for any recent version of OSX/MacOS. If you try to perform it, you will likely get a “State machine broken! level 0!” error stemming from this area in the convert.py code. I am unaware of any current fix for this as it appears the Volatility team is focusing all their efforts in the Volatility 3 build.
——
Acquiring a memory image is great, but unfortunately is useless (with respect to Volatility) without the appropriate profile to parse it. Volatility requires a memory profile be specified when parsing a memory image via the “–profile=<profile>” command line option. By default, Volatility includes a ton of profiles for Windows, but such is not the case for Linux and Mac. Though a profiles repository has been created containing a substantial set of profiles for Linux and Mac, YMMV. In my situation, I’m running the latest MacOS Sierra release 10.12.3, for which no profile existed as of this post (nor did it for 10.12.2 until I created and submitted one to the repo as well :D). Therefore, I had to create my own profile. Luckily, the folks at Volatility do a great job walking us through building a profile on a Mac. Though, there are a few clarifications I’d like to address.
To begin, I need to provide some clarification/correction for the initial step, focusing on the part in italics:
“To create a profile, you first need to download the KernelDebugKit for the kernel you want to analyze. This can be downloaded from the Apple Developer’s website (click OS X Kernel Debug Kits on the right). This account is free and only requires a valid Email address.
After the DebugKit is downloaded, mount the dmg file. This will place the contents at “/Volumes/KernelDebugKit”.”
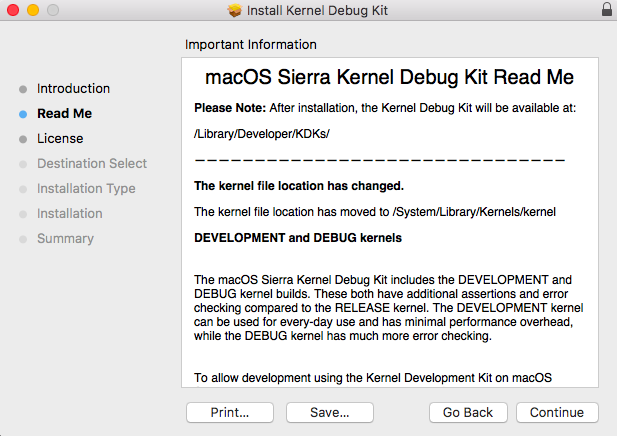
While the above statement is true, if you immediately dismount a package once it’s installed like I do, you should instead pay attention to the installer to see where it is putting the files for long term access. Independent of the mounted package, the KDK is installed in the following location, which will need to be referenced for future use once the package is dismounted post-install:
/Library/Developer/KDKs/KDK_<version>.kdk/
As of current, for macOS Sierra 10.12.2 and 10.12.3, the <version> will be “10.12.2_16C67” and “KDK_10.12.3_16D32.kdk“, respectively.
/Library/Developer/KDKs/KDK_10.12.2_16C67.kdk/
/Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/
Thus, “Step 1” for building a 10.12.3 profile would be the following (for a 64-bit 10.12.3 system):
$ dwarfdump -arch x86_64 /Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/System/Library/Kernels/kernel.dSYM > 10.12.3_x64.dwarfdump
Also note that the referenced kernel file names vary from the current instructions (e.g., “mach_kernel.dSYM” is now “kernel.dSYM”, and “mach_kernel” is now just “kernel”). So, do exercise additional caution when running the commands. For ease of reference, below should be the locations for both of these files on a macOS Sierra 10.12.3 64-bit system (but note that this may change with future versions):
/Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/System/Library/Kernels/kernel
/Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/System/Library/Kernels/kernel.dSYM
All of the above is actually noted during the install as well:
To save everyone a bit of time and translation from current Volatility documentation, I’ve written out the latest required steps below for relatively easy copy/paste into your terminal. For this, we are using the latest 10.12.3 release and associated KDK as an example:
- Check to see if a profile is already available for your particular OSX version/release
- If not, download and install the KDK appropriate for your current (or targeted) OSX version/release
- Get the dwarf debug info from the kernel.
$ dwarfdump -arch x86_64 /Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/System/Library/Kernels/kernel.dSYM > 10.12.3_x64.dwarfdump
- Convert the dwarfdump output to Linux style output readable by Volatility
$ python tools/mac/convert.py 10.12.3_x64.dwarfdump converted-10.12.3_x64.dwarfdump
- Create the types from the converted file
$ python tools/mac/convert.py converted-10.12.3_x64.dwarfdump > 10.12.3.64bit.vtypes
- Generate symbol information
$ dsymutil -s -arch x86_64 /Library/Developer/KDKs/KDK_10.12.3_16D32.kdk/System/Library/Kernels/kernel > 10.12.3.64bit.symbol.dsymutil
- Create a zip file of the *.dsymutil and *.vtypes files
$ zip 10.12.3.64bit.zip 10.12.3.64bit.symbol.dsymutil 10.12.3.64bit.vtypes- **See note at end of instructions**
- Copy the zip file to to the volatility/plugins/overlays/mac/ directory (remember, we are already inside the root /volatility directory)
$ cp 10.12.3.64bit.zip volatility/plugins/overlays/mac/
- Verify your profile is registered and ready for use
$ python vol.py --info | grep "A Profile for Mac"- The profile name presented is the string you will pass to the “–profile=” parameter when analyzing a memory image from this version/release in Volatility
**Note: While I append “x64” or “64bit” to my various output files to keep track of which architecture build I’m producing, doing so for the final .zip output file yields profile names with rather weird-looking duplicate 64-bit identifiers (e.g., “Mac10_12_3_64bitx64”). If you would like cleaner looking profile names (at the cost of losing the filename identifier denoting the arch build), you should instead drop the trailing identifier and provide a name the file like the following “10.12.3.zip”, thus yielding a prettier (IMO) profile name like “Mac10_12_3x64”.
Using Volatility for Analysis
Once we have successfully created the appropriate profile for the acquired image, we can now use the plethora of native Volatility Mac OSX plugins provided to us for analysis.
To see the list of available plugins, simply type the following:
#Executed from within the root /volatility folder of a git cloned repo
$ python vol.py --info | grep "mac_"
#Using the standalone binary
$ ./volatility_2.6_mac64_standalone --info | grep "mac_"
Conclusion
That pretty much wraps it up for this post. There is certainly more to explore with OSXpmem, the AFF4 format, and Volatility. However, I encourage you to explore it on your own as I would like to save some feature exploration for future in-depth posts focused on using both Volatility and the Rekall suite.
/JP


{kind=link}